Cuda Matrix Multiplication Optimize
Matrix multiplication in CUDA this is a toy program for learning CUDA some functions are reusable for other purposes. The use of this.

Matrix Vector Multiplication In Cuda Benchmarking Performance Stack Overflow
Optimization Overview GPU architecture Kernel optimization Memory optimization.
Cuda matrix multiplication optimize. For int k 0. Ask Question Asked 4 years 11 months ago. Baseline from the class.
We can do multiplication and inversion and yes we use a lot of warp shuffles. Optimized Parallel Tiled Approach to perform Matrix Multiplication by taking advantage of the lower latency higher bandwidth shared memory within GPU thread blocks. A warp can hold one 32 wide matrix or multiple smaller ones.
Matrix Multiplication cont 21 Optimization NVIDIA GeForce GTX 280 NVIDIA Quadro FX 5600 No optimization 88 GBps 062 GBps Coalesced using shared memory to store a tile of A 143 GBps 734 GBps Using shared memory to eliminate redundant reads of a tile of B 297 GBps 155 GBps. Suggestions for specific content can be sent to. The idea is that this kernel is executed with one thread per element in the output matrix.
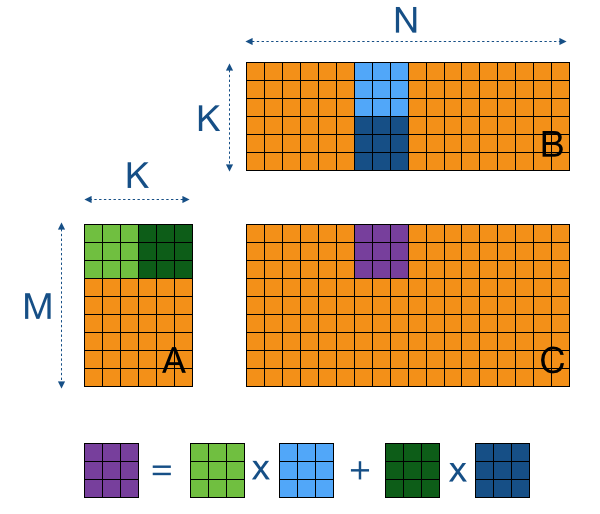
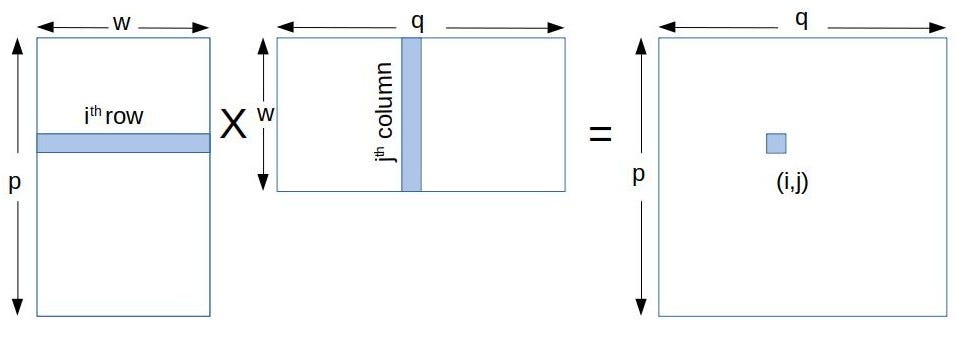
A is an M -by- K matrix B is a K -by- N matrix and C is an M -by- N matrix. As such each thread i j iterates over the entire row i in matrix A and column j in matrix B. Cuda_baselinex M Optimized code.
Please type in m n and k. For simplicity let us assume scalars alphabeta1 in the following examples. Optimization of the matrix multiplication function __global__ void Matrix_Mulfloat matrix_1 float matrix_2 float matrix_m int i blockIdxy blockDimy threadIdxy.
Go to q_node of TSUBAME qrsh -g tga-hpc-lecture -l q_node1 -l h_rt01000. Test results following tests were carried out on a Tesla M2075 card lzhengchunclus10 liu aout. Move to folder srccuda.
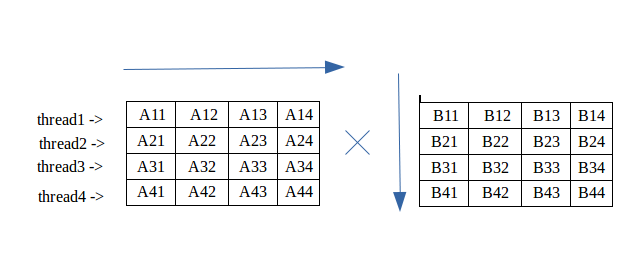
32 CUDA Cores Full IEEE 754-2008 FP32 and FP64 32 FP32 opsclock 16 FP64 opsclock. Matrix columns are distributed across the threads of a warp. We will have two executable files.
Well start with a very simple kernel for performing a matrix multiplication in CUDA. Int j blockIdxx blockDimx threadIdxx. Viewed 1k times -2.
Obvious way to implement our parallel matrix multiplication in CUDA is to let each thread do a vector-vector multiplication ie. Efficient Matrix Multiplication on GPUs GEMM computes C alpha A B beta C where A B and C are matrices. Build the files make.
This repository contains all code from the YouTube series CUDA Crash Course v3 by CoffeeBeforeArch. Run make to build the executable of this file. All loops are fully unrolled and hence the entire matrix stays in registers unless register pressure is too high.
Each element in C matrix. Optimize vector matrix multiplication in cuda with large number of zeros. Load CUDA module module load cuda.
GPGPU Programming with CUDA. Active 4 years 11 months ago. For debugging run make dbg1 to build a debuggable version of the executable binary.
E matrix_mi N j matrix_1i N k matrix_2k N j. I am using the following kernel to optimize vector-matrix multiplication for the case where both the vector and the matrix have a large number of zeros. Ifi N j N return.
Blocked Matrix Multiplication A B C CAxB Data reuse in the blocked version. Time elapsed on matrix multiplication of 1024x1024. Blocked and cached kernel.
Opencl Matrix Multiplication Sgemm Tutorial

Matrix Multiplication Cuda Eca Gpu 2018 2019

Partial Kernel Codes For Matrix Multiplication Cuda Keywords Are Bold Download Scientific Diagram

Parallel Matrix Multiplication C Parallel Processing By Roshan Alwis Tech Vision Medium
Github Kberkay Cuda Matrix Multiplication Matrix Multiplication On Gpu Using Shared Memory Considering Coalescing And Bank Conflicts

Matrix Multiplication Using Cuda Both Gpu Cpu Download Scientific Diagram

5kk73 Gpu Assignment Website 2014 2015
Multiplication Of Matrix Using Threads Geeksforgeeks

Cuda Python Matrix Multiplication Programmer Sought
Https Passlab Github Io Csce513 Notes Lecture10 Localitymm Pdf

5kk73 Gpu Assignment Website 2014 2015
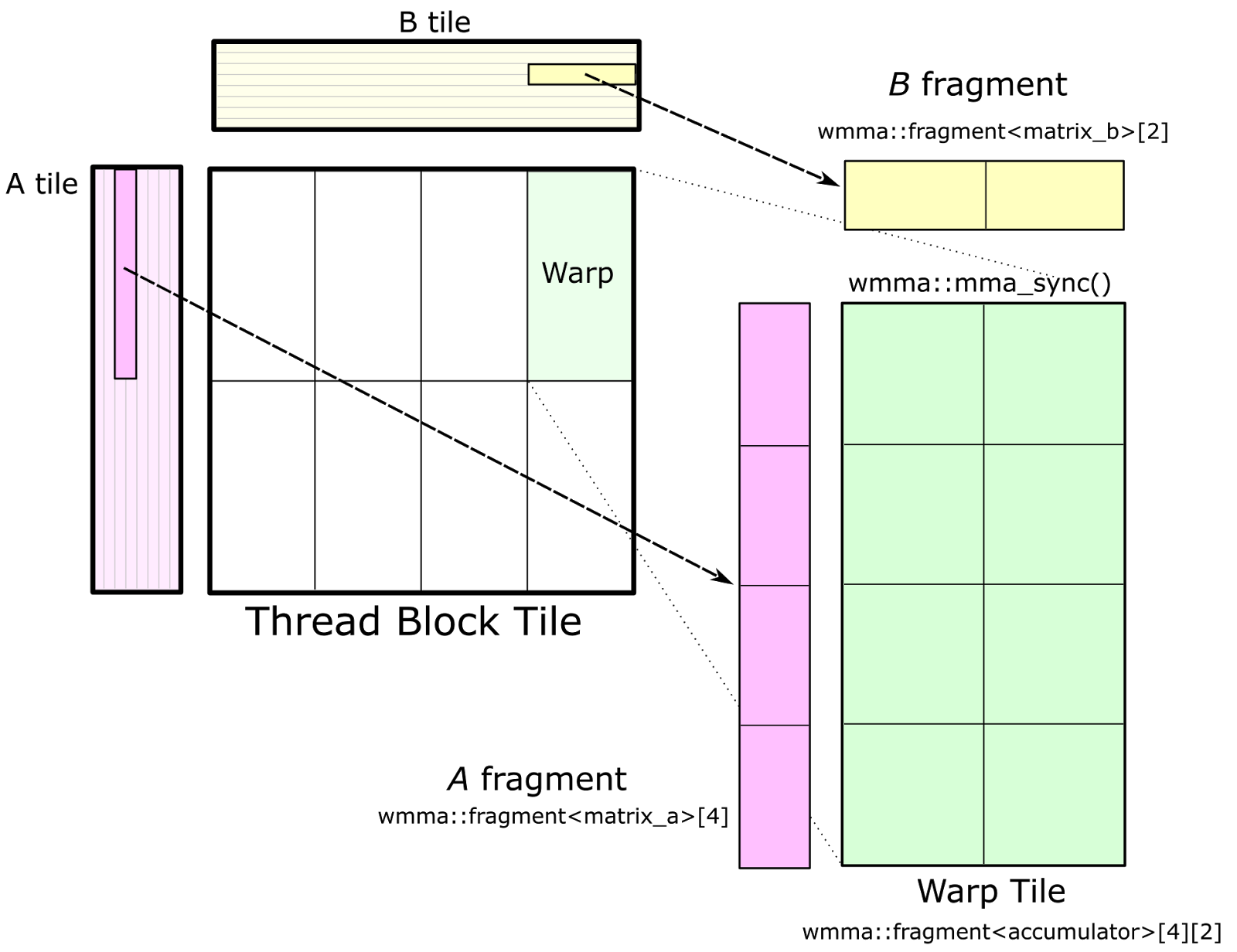
Cutlass Fast Linear Algebra In Cuda C Nvidia Developer Blog
Matrix Multiplication In Cuda A Simple Guide By Charitha Saumya Analytics Vidhya Medium

Matrix Vector Multiplication In Cuda Benchmarking Performance Stack Overflow

Matrix Multiplication Tiled Implementation With Visible L1 Cache Youtube

Tiled Algorithm An Overview Sciencedirect Topics
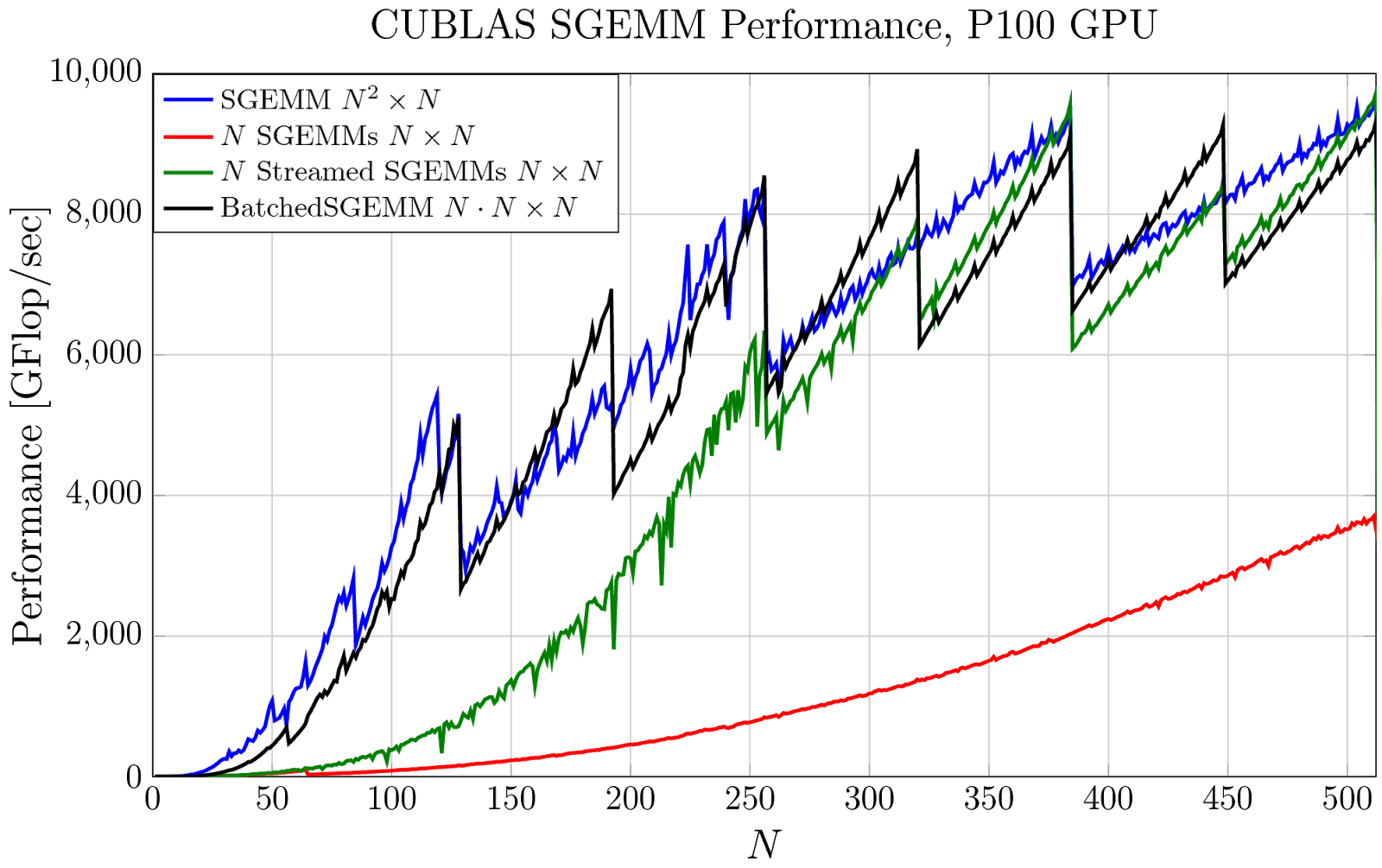
Pro Tip Cublas Strided Batched Matrix Multiply Nvidia Developer Blog

General Matrix To Matrix Multiplication Between The Current Hsi Data Download Scientific Diagram

Assignment Of Computation In Matrix Multiplication Download Scientific Diagram